BETA.INVERSE(Probabilité; Alpha; Bêta; [A]; [B])
Renvoie l’inverse de la fonction de densité de distribution de la probabilité suivant une loi bêta cumulé.
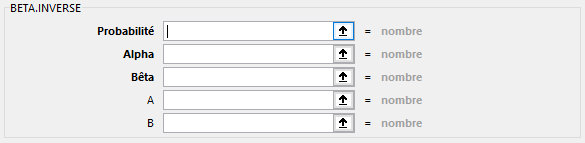
Probabilité : Obligatoire. Représente la probabilité associée à la distribution bêta.
alpha : Obligatoire. Représente un paramètre de la distribution.
bêta : Obligatoire. Représente un paramètre de la distribution.
A : Facultatif. Représente une limite inférieure de l’intervalle des x.
B : Facultatif. Représente une limite supérieure de l’intervalle des x.
CENTILE(Matrice; K)
Renvoie le k-ième centile des valeurs d’une plage. Cette fonction vous permet de définir un seuil d’acceptation. Par exemple, vous pouvez décider de n’étudier que les candidats ayant obtenu un résultat supérieur au 90e centile.

CONCATENER(Texte1; [Texte2];…)
La fonction CONCATENER, permet de joindre plusieurs chaînes au sein d’une seule chaîne.

COVARIANCE(Matrice1; Matrice2)
Renvoie la covariance, moyenne des produits des écarts pour chaque paire de points de données dans deux jeux de données.
Utilisez la covariance pour déterminer la relation entre deux jeux de données. Par exemple, vous pouvez vérifier si les revenus supérieurs vont de pair avec des niveaux avancés d’éducation.

CRITERE.LOI.BINOMIALE(Tirages; Probabilité_succès; Alpha)
Renvoie la plus petite valeur pour laquelle la distribution binomiale cumulée est supérieure ou égale à une valeur de critère. Utilisez cette fonction pour des applications d’assurance qualité. Par exemple, la fonction CRITERE.LOI.BINOMIALE vous permet de déterminer le nombre maximal de pièces défectueuses autorisées à la sortie d’une chaîne d’assemblage sans que le lot entier soit rejeté.

ECARTYPE(Nombre1; [Nombre2];…)
Evalue l’écart type d’une population en se basant sur un échantillon de cette population. L’écart type est une mesure de la dispersion des valeurs par rapport à la moyenne (valeur moyenne).

ECARTYPEP(Nombre1; [Nombre2];…)
Calcule l’écart type d’une population à partir de la population entière telle que la déterminent les arguments. L’écart type est une mesure de la dispersion des valeurs par rapport à la moyenne (valeur moyenne).

INTERVALLE.CONFIANCE(Alpha; Écart_type ; Taille)
Renvoie l’intervalle de confiance pour la moyenne d’une population, à l’aide d’une distribution normale.
L’intervalle de confiance est une plage de valeurs. Votre moyenne d’échantillonnage, x, se trouve au centre de cette plage, et la plage est x ± INTERVALLE.CONFIANCE. Par exemple, si x est la moyenne d’échantillonnage des délais de livraison des articles commandés par courrier, x ± INTERVALLE.CONFIANCE est une plage de moyennes d’échantillonnage. Pour une moyenne de population au hasard, μ0, dans cette plage, la probabilité d’obtenir une moyenne d’échantillonnage plus éloignée de μ0 que x est plus élevée que alpha ; pour une moyenne de population au hasard, μ0, en dehors de cette plage, la probabilité d’obtenir une moyenne d’échantillonnage plus éloignée μ0 que x est inférieure à alpha. En d’autres termes, supposons que nous utilisons x, standard_dev et size pour construire un test bilatéral au niveau critique alpha de l’hypothèse selon laquelle la moyenne de population est µ0. Dans ce cas, nous ne rejetterons pas l’hypothèse si µ 0 se trouve dans l’intervalle de confiance, mais bien si μ0 ne s’y trouve pas. L’intervalle de confiance ne nous permet pas de déduire qu’il y a une probabilité de 1 – alpha que notre prochain paquet ait un délai de livraison situé dans l’intervalle de confiance.

INVERSE.LOI.F(Probabilité ; Degrés_liberté1; Degrés_liberté2)
Renvoie l’inverse de la distribution de probabilité F (unilatérale à droite). Si p = LOI.F(x,…), alors INVERSE.LOI.F(p,…) = x.
La distribution F peut être utilisée dans un test F qui compare le degré de dispersion de deux ensembles de données. Par exemple, vous pouvez analyser les distributions de revenus en France et en Allemagne pour déterminer si les deux pays ont le même degré de diversité.

KHIDEUX.INVERSE(Probabilité; Degrés_liberté)
Renvoie l’inverse de la probabilité unilatérale à droite de la distribution khi-deux. Si probabilité = LOI.KHIDEUX(x,…), alors KHIDEUX.INVERSE(probabilité,…) = x. Utilisez cette fonction pour comparer les résultats obtenus aux résultats prévus, afin de déterminer si votre hypothèse de départ était juste.

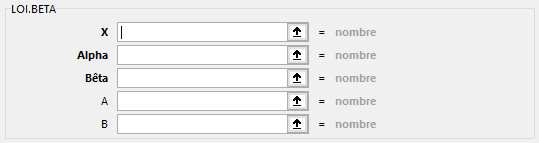
LOI.BETA(X; Alpha; Bêta; [A]; [B])
Renvoie la fonction de densité de distribution de la probabilité suivant une loi bêta cumulée. Cette fonction de distribution bêta est généralement utilisée pour étudier la variation du pourcentage d’un élément présent dans des échantillonnages, par exemple, la durée quotidienne pendant laquelle les gens regardent la télévision.
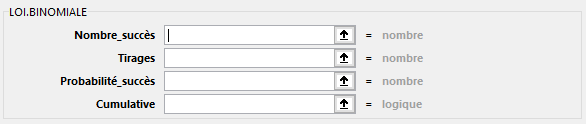
LOI.BINOMIALE(Nombre_succès; Tirages; Probabilité_succès; Cumulative)
Renvoie la probabilité d’une variable aléatoire discrète suivant la loi binomiale. Utilisez la fonction LOI.BINOMIALE pour résoudre des problèmes comportant un nombre de tests ou d’essais déterminé, lorsque le résultat des essais ne peut être qu’un succès ou un échec, lorsque les essais sont indépendants ou lorsque la probabilité de succès est constante au cours des expérimentations. La fonction LOI.BINOMIALE peut, par exemple, calculer la probabilité pour que deux des trois enfants à naître soient des garçons.
LOI.BINOMIALE.NEG(Nombre_échecs; Nombre_succès; Probabilité_succès)
Renvoie la probabilité d’une variable aléatoire discrète suivant une loi binomiale négative. La fonction LOI.BINOMIALE.NEG renvoie la probabilité d’obtenir un nombre d’échecs égal à l’argument nombre_échecs avant de parvenir au succès dont le rang est donné par l’argument nombre_succès, lorsque la probabilité de succès, définie par l’argument probabilité_succès, est constante. Cette fonction est similaire à la loi binomiale, à la différence que le nombre de succès est fixe et le nombre d’essais variable. Comme pour la loi binomiale, les essais sont supposés indépendants.
Par exemple, vous devez trouver 10 personnes possédant d’excellents réflexes et vous savez que la probabilité qu’un candidat présente cette qualité est de 0,3. La fonction LOI.BINOMIALE.NEG.N calcule la probabilité de recevoir un certain nombre de candidats non qualifiés avant de parvenir à réunir les 10 candidats recherchés.

LOI.EXPONENTIELLE(X; Lambda; Cumulative)
Renvoie la distribution exponentielle. Utilisez la fonction LOI.EXPONENTIELLE pour prévoir la durée séparant des événements, tel le temps mis par un distributeur automatique bancaire pour délivrer de l’argent. Par exemple, vous pouvez utiliser LOI.EXPONENTIELLE pour calculer la probabilité que l’opération dure moins d’une minute.

LOI.F(X; Degrés_liberté1; Degrés_liberté2)
Renvoie la probabilité (unilatérale à droite) d’une variable aléatoire suivant une loi F pour deux jeux de données. Vous pouvez utiliser cette fonction pour déterminer si deux jeux de données ont des degrés de diversité différents. Par exemple, vous pouvez comparer les résultats de tests soumis aux garçons et aux filles à l’entrée à l’université et déterminer si la dispersion parmi les filles est la même que parmi les garçons.

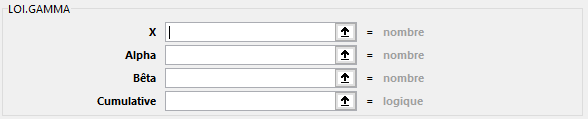
LOI.GAMMA(X; Alpha; Bêta; Cumulative)
Renvoie la probabilité d’une variable aléatoire suivant une loi Gamma. Vous pouvez utiliser cette fonction pour étudier des variables dont la distribution est susceptible d’être asymétrique. La loi gamma est couramment utilisée dans l’étude de files d’attente.
LOI.GAMMA.INVERSE(Probabilité; Alpha; Bêta)
Renvoie, pour une probabilité donnée, la valeur d’une variable aléatoire suivant une loi Gamma. Si l’argument p = LOI.GAMMA(x;…), la fonction LOI.GAMMA.INVERSE(p;…) = x.
Vous pouvez utiliser cette fonction pour étudier une variable dont la distribution est susceptible d’être asymétrique.

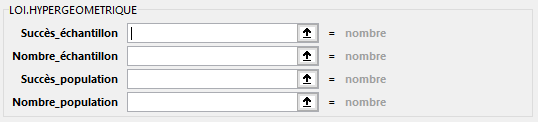
LOI.HYPERGEOMETRIQUE(Succès_échantillon; Nombre_échantillon; Succès_population; Nombre_population)
Renvoie la loi hypergéométrique. La fonction LOI.HYPERGEOMETRIQUE renvoie la probabilité d’obtenir un nombre donné de tirages « succès » sur un échantillon, connaissant la taille de l’échantillon, le nombre de succès de la population et sa taille. Utilisez la fonction LOI.HYPERGEOMETRIQUE dans des problèmes supposant une population déterminée, dans lesquels chaque observation est soit un succès, soit un échec et où chaque sous-ensemble d’une taille donnée est constitué avec la même vraisemblance.
LOI.KHIDEUX(X; Degrés_liberté)
Renvoie la probabilité unilatérale à droite de la distribution khi-deux. La distribution χ2 est associée à un test χ2. Utilisez un test χ2 pour comparer les valeurs obtenues aux valeurs prévues. Par exemple, une expérience génétique fait l’hypothèse que la prochaine génération de plantes présentera un ensemble de couleurs donné. En comparant les résultats obtenus aux résultats prévus, vous pouvez déterminer si votre hypothèse de départ était correcte.

LOI.LOGNORMALE(X; Espérance; Écart_type)
Renvoie la distribution de x suivant une loi lognormale cumulée, où ln(x) est normalement distribué à l’aide des paramètres moyenne et écart_type. Cette fonction vous permet d’analyser des données après leur transformation logarithmique.

LOI.LOGNORMALE.INVERSE(Probabilité; Espérance; Écart_type)
Renvoie l’inverse de la fonction de distribution de x suivant la loi lognormale cumulée, où ln(x) est normalement distribué avec les paramètres espérance et écart_type. Si p = LOI.LOGNORMALE(x;…), alors LOI.LOGNORMALE.INVERSE(p;…) = x.
Utilisez la distribution lognormale pour analyser des données transformées de manière logarithmique.

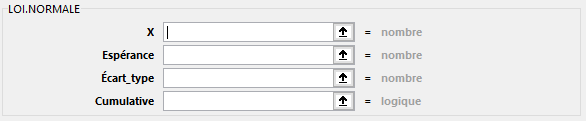
LOI.NORMALE(X; Espérance; Écart_type; Cumulative)
Renvoie la distribution normale pour la moyenne et l’écart type spécifiés. Cette fonction a de nombreuses applications en statistique, y compris dans les tests d’hypothèse.
LOI.NORMALE.INVERSE(Probabilité; Espérance; Écart_type)
Renvoie, pour une probabilité donnée, la valeur d’une variable aléatoire suivant une loi normale pour la moyenne et l’écart type spécifiés.

LOI.NORMALE.STANDARD(Z)
Renvoie la probabilité d’une variable aléatoire continue suivant une loi normale standard (ou centrée réduite). Cette distribution a une moyenne égale à 0 (zéro) et un écart type égal à 1. La présente fonction remplace l’usage de la table donnant la valeur des aires comprises sous une courbe normale centrée réduite.

LOI.NORMALE.STANDARD.INVERSE(Probabilité)
Renvoie, pour une probabilité donnée, la valeur d’une variable aléatoire suivant une loi normale standard (ou centrée réduite). Cette distribution a une moyenne égale à zéro et un écart type égal à 1.

LOI.POISSON(X; Espérance; Cumulative)
Renvoie la probabilité d’une variable aléatoire suivant une loi de Poisson. Une application courante de la loi de Poisson est la prédiction du nombre d’événements susceptibles de se produire sur une période de temps déterminée, par exemple, le nombre de voitures qui se présentent à un poste de péage en l’espace d’une minute.

LOI.STUDENT(X; Degrés_liberté; Uni/Bilatéral)
Renvoie la probabilité d’une variable aléatoire suivant la loi de t de Student, dans laquelle une valeur numérique (x) est une valeur calculée de t dont il faut calculer la probabilité. La loi de t est utilisée pour les tests d’hypothèse sur des échantillons de petite taille. Utilisez cette fonction au lieu d’une table des valeurs critiques de la loi de t.

LOI.STUDENT.INVERSE(Probabilité; Degrés_liberté)
Renvoie, pour une probabilité donnée, la valeur inverse bilatérale d’une variable aléatoire suivant une loi T de Student.

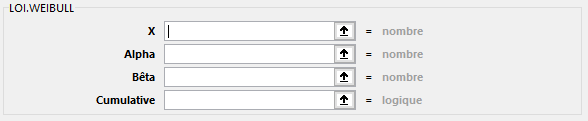
LOI.WEIBULL(X; Alpha; Bêta; Cumulative)
Renvoie la probabilité d’une variable aléatoire suivant une loi Weibull. Utilisez cette distribution dans une analyse de fiabilité telle que le calcul du temps moyen de fonctionnement sans panne d’un appareil.
MODE(Nombre1; [Nombre2], …)
Supposons que vous voulez déterminer le nombre plus courante d’espèce vue dans un échantillon de rencontrées une zone humide sensible et sur une période de 30 ans, ou que vous voulez connaître le nombre plus fréquent des appels téléphoniques dans un centre de support par téléphone pendant désactiver pois heures k. Pour calculer le mode d’un groupe de nombres, utilisez la fonction MODE.
MODE renvoie la valeur plus fréquente ou répétitive, dans une matrice ou une plage de données.

PLAFOND(Nombre; Précision)
Renvoie l’argument nombre après l’avoir arrondi au multiple de l’argument précision en s’éloignant de zéro. Par exemple, si vous voulez que la valeur décimale de vos prix soit toujours un multiple de 5 centimes, et que le prix de votre produit est 4,42 F, utilisez la formule =PLAFOND(4,42;0,05) pour arrondir les centimes au multiple de 5 supérieur.

PLANCHER(Nombre; Précision)
Arrondit l’argument nombre au multiple de l’argument précision immédiatement inférieur (tendant vers zéro).

PREVISION(X; Y_connus; X_connus)
Calcule ou prévoit une valeur capitalisée à partir de valeurs existantes. La valeur prévue est une valeur x pour une valeur y donnée. Les valeurs connues sont des valeurs x et y existantes, et la nouvelle valeur prévue est calculée par la méthode de régression linéaire. Vous pouvez utiliser cette fonction pour établir des prévisions de ventes, des besoins en stock ou des tendances de consommation.

QUARTILE(Matrice; Quart)
Renvoie le quartile d’une série de données. Les quartiles sont souvent utilisés pour les données relatives aux ventes et aux enquêtes afin de séparer les populations en groupes. Ainsi, vous pouvez utiliser la fonction QUARTILE pour déterminer les vingt-cinq pour cent de revenus les plus élevés d’une population.

RANG(Nombre; Référence; [Ordre])
Renvoie le rang d’un nombre dans une liste d’arguments. Le rang d’un nombre est donné par sa taille comparée aux autres valeurs de la liste. (Si vous deviez trier la liste, le rang d’un nombre serait sa position).

RANG.POURCENTAGE(Matrice; X; [Précision])
Renvoie le rang d’une valeur d’une série de données sous forme de pourcentage. Cette fonction vous permet d’évaluer la position relative d’une valeur dans une série de données. Par exemple, vous pouvez utiliser la fonction RANG.POURCENTAGE pour évaluer la position d’un résultat à un test d’aptitude parmi tous les résultats à ce test.

TEST.F(Matrice1; Matrice2)
Renvoie le résultat d’un test F. Un test F renvoie la probabilité bilatérale que les variances des arguments matrice1 et matrice2 ne présentent pas de différences significatives. Utilisez cette fonction pour comparer les variances de deux échantillons. Par exemple, à partir des résultats d’examens dans des écoles publiques et privées, vous pouvez déterminer si ces écoles présentent des degrés de diversité différents en termes de résultats.

TEST.KHIDEUX(Plage_réelle; Plage_attendue)
Renvoie le test d’indépendance. TEST.KHIDEUX renvoie la valeur de la distribution khi-deux (χ2) pour la statistique et les degrés de liberté appropriés. Utilisez les tests χ2 pour déterminer si les résultats prévus sont vérifiés par une expérimentation.

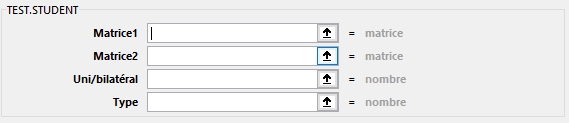
TEST.STUDENT(Matrice1; Matrice2; Uni/Bilatéral; Type)
Renvoie la probabilité associée à un test T de Student. Utilisez la fonction TEST.STUDENT pour déterminer dans quelle mesure deux échantillons sont susceptibles de provenir de deux populations sous-jacentes ayant la même moyenne.
TEST.Z(Matrice; X; [Sigma])
Renvoie la valeur-probabilité unilatérale d’un test z. Pour une moyenne de population supposée donnée, μ0, TEST.Z renvoie la probabilité que la moyenne d’échantillonnage soit supérieure à la moyenne des observations dans l’ensemble de données (matrice), à savoir la moyenne d’échantillonnage observée.
Pour en savoir plus sur l’utilisation de TEST.Z dans une formule pour calculer une valeur de probabilité bilatérale, reportez-vous aux « Remarques » ci-dessous.

VAR(Nombre1; [Nombre2];…)
Calcule la variance sur la base d’un échantillon.

VAR.P(Nombre1; [Nombre2];…)
Calcule la variance sur la base de l’ensemble de la population (ignore les valeurs logiques et le texte de la population).

